Cracking Trivia: A Software Engineer's Approach to TapTap Live
Disclaimer: This exploration was conducted solely for educational purposes on screen recordings of the app and was not deployed during live games.
Introduction
TapTap Live, a mobile app for iOS, hosts live trivia games reminiscent of the app HQ. Players aim to correctly answer a series of 12 trivia questions to win a share of the daily pot, typically amounting to $250. As a Software Engineering student, I saw this app not just as entertainment but as a perfect opportunity to apply and challenge my software engineering skills. This blog post details my journey to automate the trivia answer process, featuring the final product demo and the evolutionary steps of my solution. Here’s the most recent final product in action:
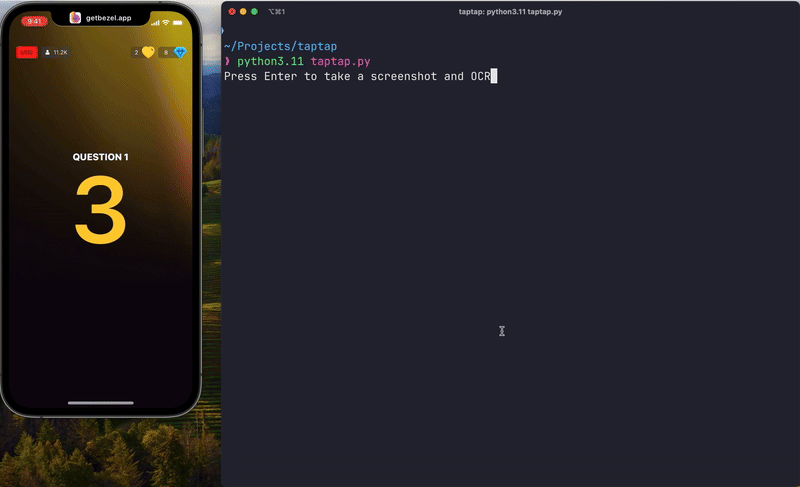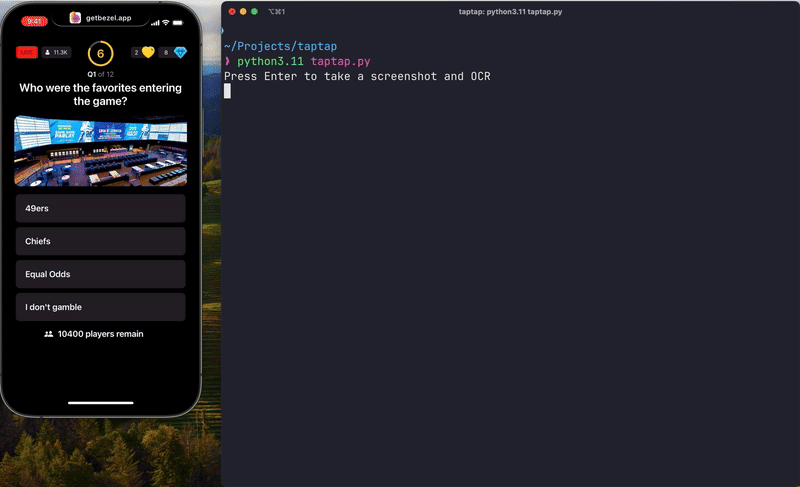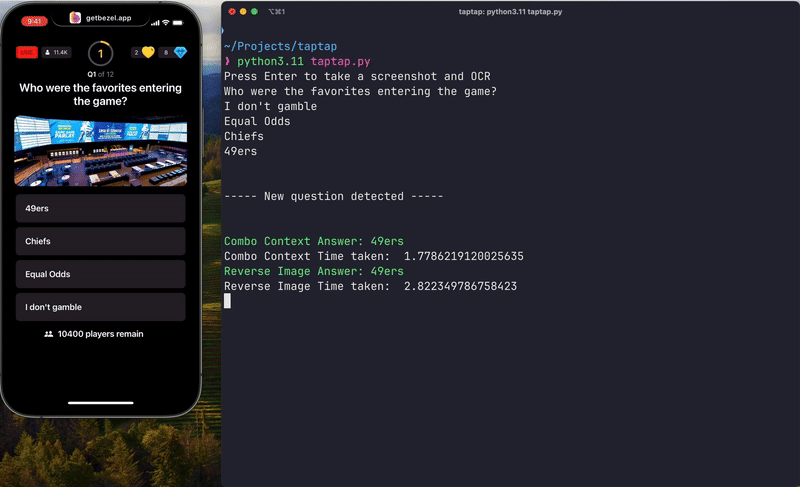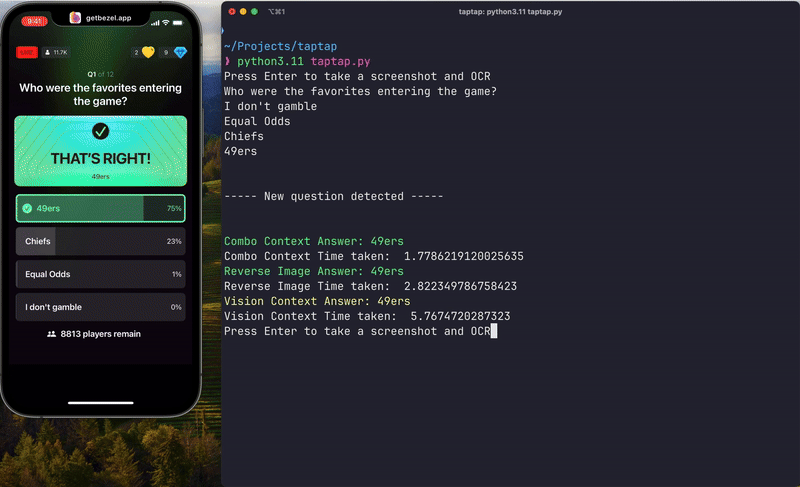
Now let me explain how I got here…
Designing and developing this script was much like solving a LeetCode problem given during an interview, the quick and dirty solution (naive approach) is typically where to start.
Initial Approach: The Naive Solution
When first looking at this problem, there were a few things that came to mind:
- We can probably use OCR/text recognition to get the text from the screen
- We can probably give that text to GPT-4
- GPT-4 can probably give us the correct answer from that
With that general layout in mind, I got to work on coding. I used PyTesseract to extract all of the text, then using my OpenAI developer API access, I sent that to GPT-4-Turbo for processing with a prompt that would encourage GPT-4 to return just the word of the correct answer. This one word response was designed with the hope that this would increase response time since it’s minimizing the number of tokens GPT-4 needs to generate and reply with.
Data Flow Visualization:
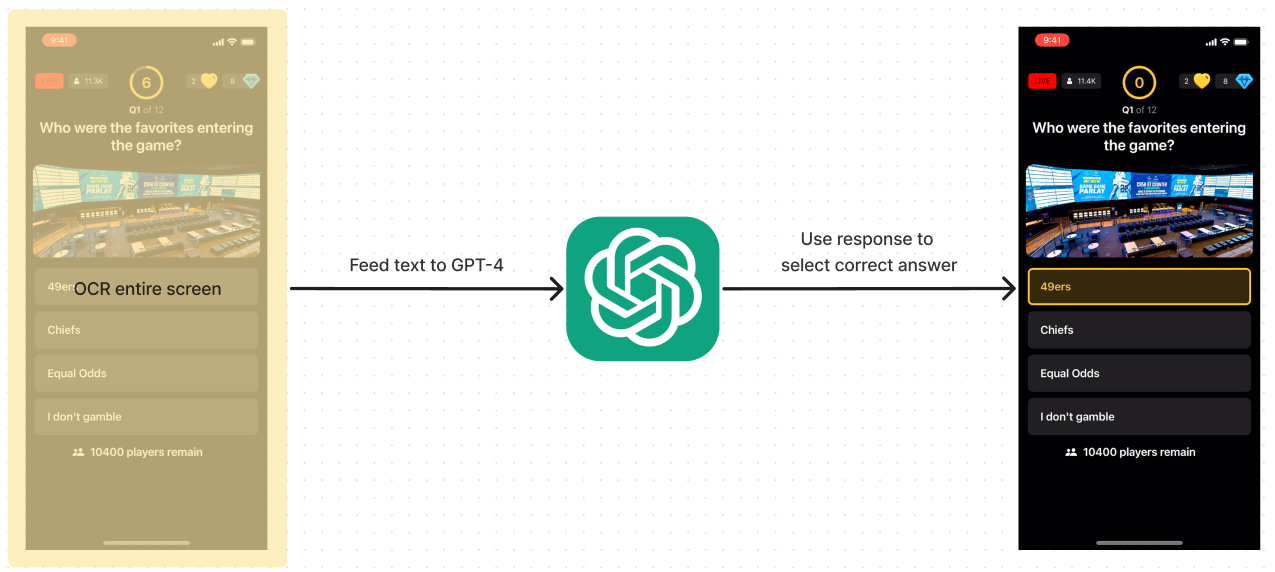
On the surface, this seems like it would work, however there’s one key factor that pretty much causes this approach to be dead in the water… recent events. GPT-4 is only trained on data up to April 2023, and TapTap Live very clearly asks questions about recent events. So, this sent me back to the drawing board. I spent some time figuring out ways to help this, until it hit me that a simple solution that could work would be to Google the question and give that as context to GPT-4 to help ground and make the response more accurate. This idea alone presents another challenge, how could I extract just the question from the screenshot?
Rethinking Strategy: Enhancing Accuracy
My first approach was to do the following:
- Use GPT-4-Vision to extract the question and answers from the image
- Using the question provided by GPT-4-Vision, Google it and use the search results as context for the next step
- Using the question, answers, and context provided by Google, prompt GPT-4-Turbo for the most likely correct answer
Improved Data Flow Diagram:
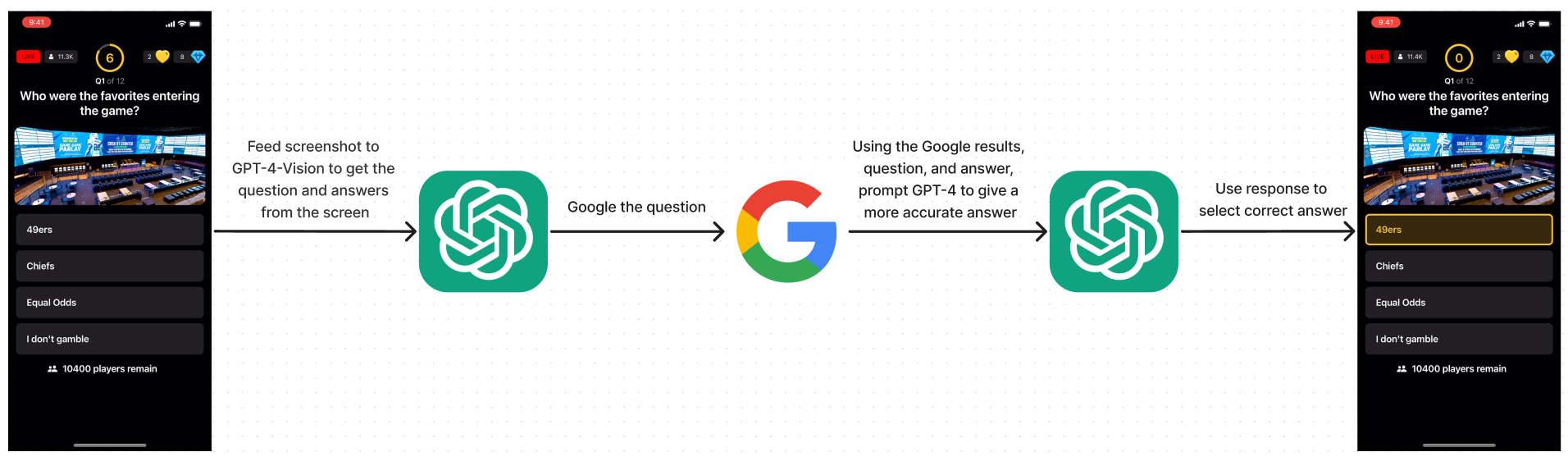
This proved to be successful, I was getting more accurate answers, however the huge drawback was that it was too slow. Calling back to tech interview questions, this is where optimization comes into play. I have a solution that works, but in practice, this is too slow to be useful, as we only have about 7 seconds to provide a response and the total time from scanning to getting an answer was taking about 8 seconds. Not practical. So how can I find the balance between speed and accuracy.
Optimization: Balancing Speed and Accuracy
After thinking about ways to increase the speed, it’s clear that sending 2 requests to the OpenAI API is too much. We need a way to get that down to 1 request. This means either getting rid of the request to get the correct answer, which we would prefer not to do since that request is typically extremely accurate (more on this later) or getting rid of the request to get the question and answer from the screen.
How could we do this? After talking with friends (s/o Marcus and Sami), I realized I had already worked on a way to get the text from the screen locally using OCR. However, I didn’t consider this further since the OCR was picking up too many extra characters to actually provide something consistent to parse through to get the question and answer accurately. However, as suggested by my friends, a better approach to getting the question and answer from the text wasn’t to figure out a way to parse all the text from the screen, but instead, only scan the segments of the screen that had the information I needed.
Selective Scanning Visualization:
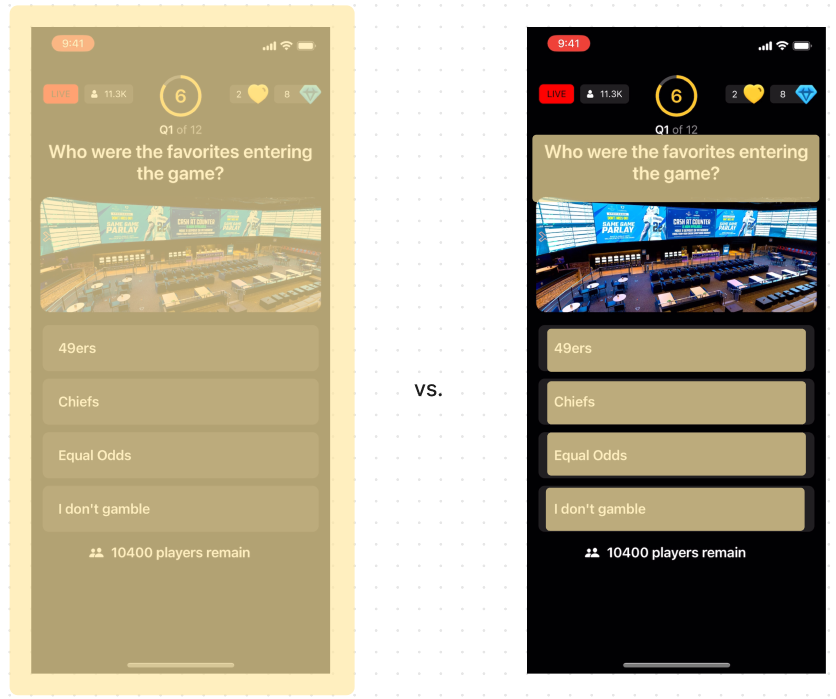
By only “highlighting” the important segments, the OCR has nothing to scan except for the question and the answers. I was able to get this working, however it proved quite difficult to consistently do since the question could be 1, 2, or 3 lines long and this caused the image and answers to be pushed down as well. However, after working some magic with OpenCV, I had developed an algorithm for consistently picking out the top_left_x, top_left_y, height, and width of each area I needed to scan. Here’s a diagram of how the data flows now that I could get rid of the first GPT-4-Vision request:

With this improvement, I was able to cut down the response time to about 2 seconds on average since the Vision processing took up a majority of the processing time. This meant the program would work for live usage! This was still one small problem however…
Addressing Image-Based Questions: Google’s Gemini Vision
In addition to using recent events, TapTap Live also has questions like the following:
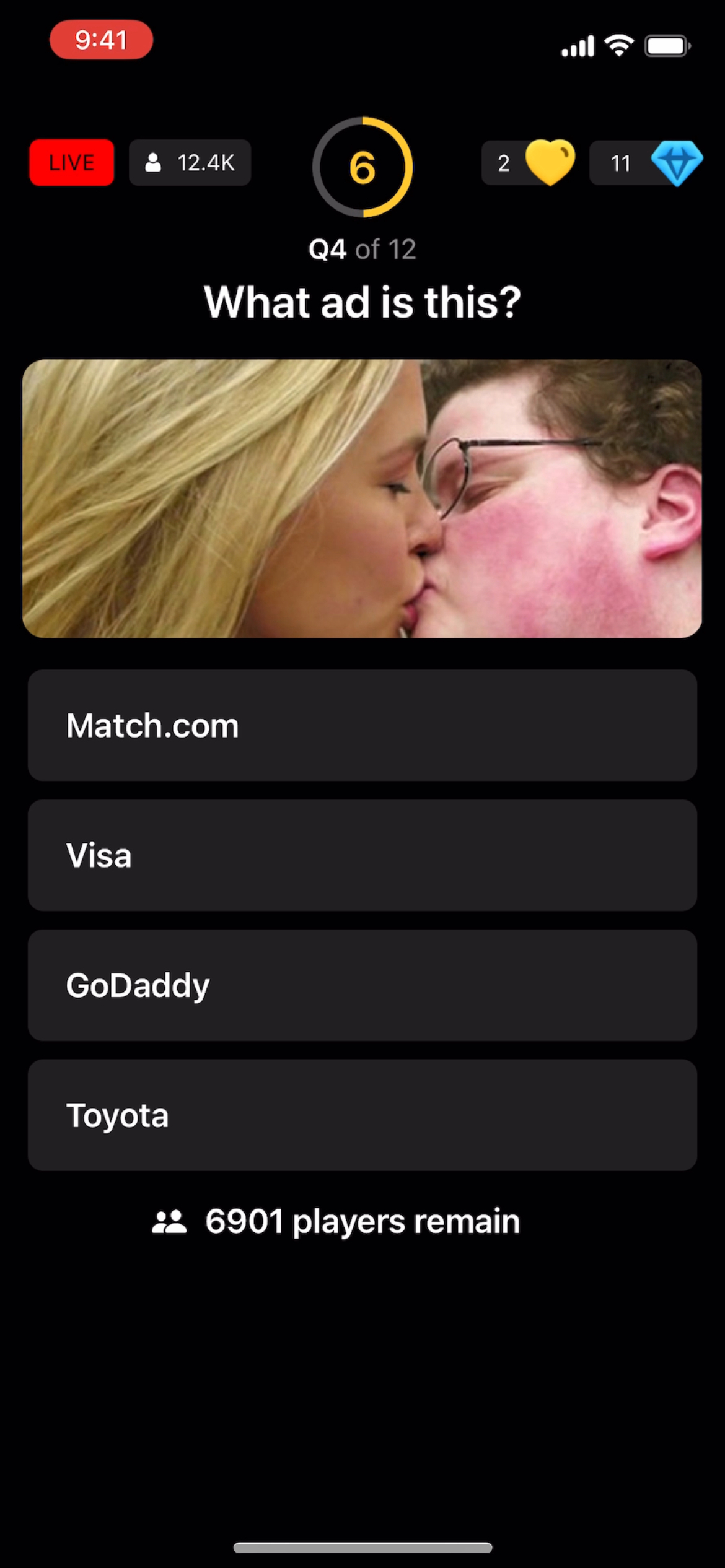
Clearly, giving GPT-4 a prompt asking it to deduce what ad this is with only text would not work. The response I would get was pretty much random (however it did typically lean towards Toyota). With all this in mind, the next hurdle was figuring out how to handle a question that is relevant to the image on the screen.
The first solution I came up with involved using Google’s Gemini Vision (I decided to go with Google’s Gemini Vision instead of GPT-4-Vision since I had already run up quite a bill due to my OpenAI API). When figuring out how to integrate Gemini Vision, I realized I still needed context from a Google Search query as this was pretty crucial to getting accurate answers based on recent events, however I also couldn’t just Google a question like “What ad is this?” and hope to get something relevant to the trivia question I was trying to solve. So I decided to revert back to a double API request approach.
Dual API Request Flow:
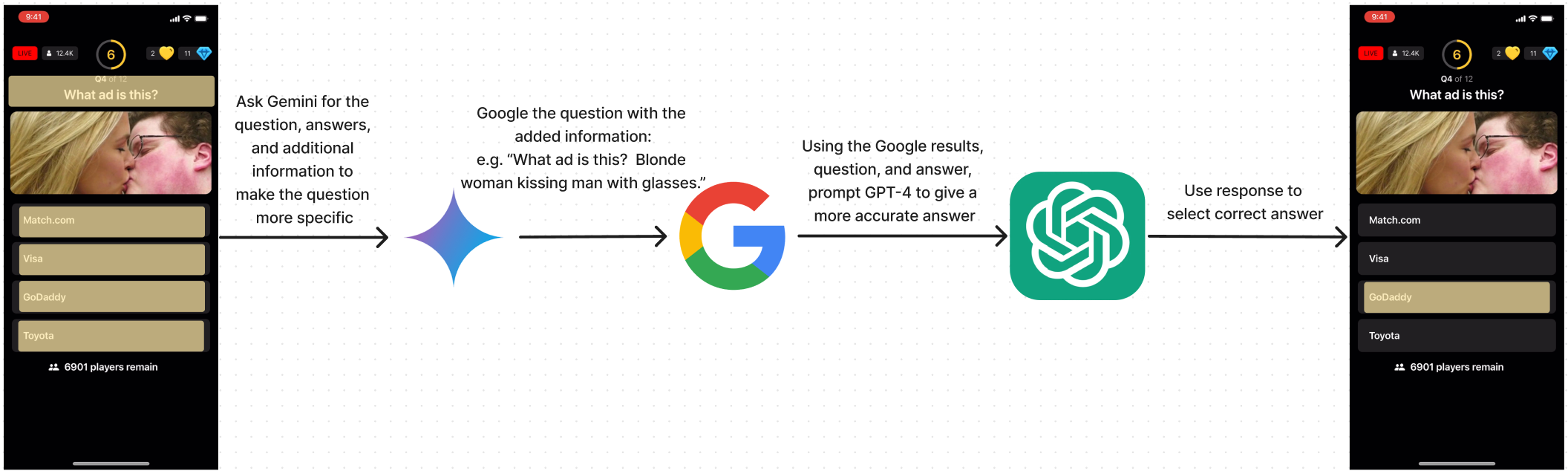
The first request would be to Google’s Gemini Pro Vision API. This would prompt Gemini to look at the screenshot, deduce what the question and answers were, and also look at the image in the screenshot, if it deemed it was relevant to the question, append whatever information would be necessary (in string format) to make the question more specific. As an example, the response I would get back for the question from above would be something like “What ad is this? Blonde woman kissing man with glasses.” With a question like this, I could execute a Google search more accurately. Ultimately providing better context for the next request. The next request didn’t really change. It involved prompting GPT-4-Turbo with the question, answers, and the context provided from the Google search.
This approach proved to be effective, with the addition of the specific querying via Google, GPT-4 had much more specific context to work with and would consistently guess accurately. However, the original issue of speed returned with this approach.
The Goldilocks Solution: Fast and Accurate
With these 2 approaches alone, I already had a script that would consistently give me accurate answers. The first solution of using OCR + Turbo-4 proved to be super fast and effective when the picture doesn’t matter, and the Gemini Vision + Turbo-4 proved to be extremely accurate in any case, however, it was much slower, typically around 7 seconds. So waiting for its response would typically be cutting it pretty close. For the time being though, I was happy with those solutions and decided to keep them both in the script. With both functions written, I could easily call both in different threads and have them run simultaneously. However, I wasn’t satisfied, I wanted to find the Goldilocks solution. The best balance of speed and accuracy.
After consulting with other people about ideas (s/o Sami), I decided to try reverse image searching the picture. This would be much faster than Gemini Pro Vision since reverse image search doesn’t really analyze the image but rather tries to match it and provide relevant search results. After tinkering with Google search and writing methods to send the image to Google, I was able to consistently get an array of strings made up of the results from the reverse image search. With this, I would use the first approach and pass the question, answer, Google search context, and reverse image search context to GPT-4-Turbo. This proved to work just about as well as the Gemini Pro Vision (more testing still needs to be done). With that, I had my ideal solution (for the time being).
Once again, here’s a demo of the final working version:
Conclusion: Reflections and Learning
This journey from the initial naive approach to finding a “Goldilocks solution” for automating trivia answers on TapTap Live has been a testament to the iterative process of software engineering. It’s a vivid example of how combining different technologies and strategies can solve complex problems, albeit for a light-hearted application like a trivia game. The final solution incorporates OCR, AI, and strategic use of APIs to strike a balance between speed and accuracy, a challenge often faced in real-world software development.
This project was not only a fun and challenging way to apply my skills but also a learning experience that mirrored the problem-solving process in professional software engineering. Facing limitations, iterating on solutions, and ultimately finding a balance between competing requirements are all part of the day-to-day life of a software engineer.
For fellow students and professionals alike, I hope this dive into my project serves as inspiration to tackle your projects with curiosity and persistence. Whether it’s automating trivia answers, developing a new app, or solving a complex algorithm, the journey is filled with learning opportunities and the satisfaction of overcoming challenges.